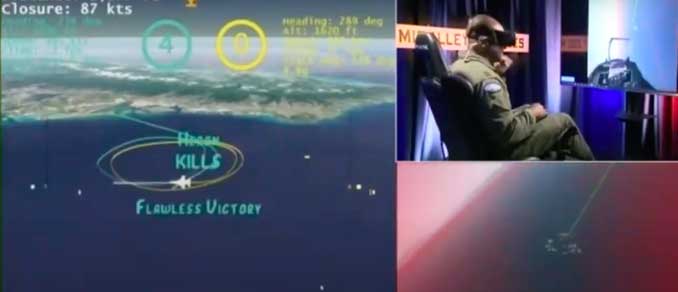
 La interminable saga de máquinas que superan a los humanos acaba de escribir un nuevo capítulo. Un algoritmo de IA ha vuelto a vencer a un piloto de caza humano en un combate virtual. El concurso fue el final del desafío AlphaDogfight de la Fuerza Aérea de EE.UU., un proyecto para «demostrar la viabilidad de desarrollar agentes autónomos eficaces e inteligentes capaces de derrotar a las aeronaves adversarias en un combate aéreo».
La interminable saga de máquinas que superan a los humanos acaba de escribir un nuevo capítulo. Un algoritmo de IA ha vuelto a vencer a un piloto de caza humano en un combate virtual. El concurso fue el final del desafío AlphaDogfight de la Fuerza Aérea de EE.UU., un proyecto para «demostrar la viabilidad de desarrollar agentes autónomos eficaces e inteligentes capaces de derrotar a las aeronaves adversarias en un combate aéreo».
En agosto pasado, la Agencia de Proyectos de Investigación Avanzada de Defensa, o DARPA, seleccionó ocho equipos, que iban desde grandes contratistas tradicionales de defensa como Lockheed Martin, hasta pequeños grupos como Heron Systems, para competir en una serie de pruebas en noviembre y enero.
En la final, el 20 de agosto, Heron Systems salió victoriosa contra los otros siete equipos, después de dos días de combates aéreos a la antigua usanza, yendo los cazas uno tras el otro, usando sólo armas de fuego de proa. Heron se enfrentó a un piloto de combate humano sentado en un simulador y con un casco de realidad virtual, y ganó cinco asaltos a cero.
El otro ganador en el evento del jueves fue el aprendizaje de refuerzo profundo, en el que, los algoritmos de inteligencia artificial consiguen probar una tarea en un entorno virtual una y otra vez, a veces muy rápidamente, hasta que desarrollan algo como la comprensión. El refuerzo profundo jugó un papel clave en los agentes de Heron System y de Lockheed Martin, el segundo finalista.
Matt Tarascio, vicepresidente de inteligencia artificial, y Lee Ritholtz, director y arquitecto jefe de inteligencia artificial, de Lockheed Martin, dijeron a Defense One que, intentar que un algoritmo funcione bien en el combate aéreo es muy diferente a enseñar a un software simplemente a «volar», o a mantener una dirección, altitud y velocidad determinadas. El software comenzará con una completa falta de comprensión incluso de las tareas de vuelo más básicas, explicó Ritholtz, poniéndolo en desventaja frente a cualquier humano, al principio: «No tienes que enseñarle a un humano [que] no debería estrellarse contra el suelo… Tienen instintos básicos que el algoritmo no tiene», en términos de entrenamiento. «Eso significa morir mucho. Golpear el suelo, mucho», dijo Ritholtz.
Tarascio lo comparó con «poner a un bebé en una cabina».
Superar esa ignorancia requiere enseñar al algoritmo que hay un coste por cada error, pero que esos costes no son siempre iguales. El refuerzo entra en juego cuando el algoritmo, basado en una simulación tras otra, asigna pesos [costes] a cada maniobra, y luego reasigna esos pesos a medida que se actualizan las experiencias.
Aquí, también, el proceso varía enormemente dependiendo de las experiencias adquiridas, incluyendo los sesgos conscientes e inconscientes de los programadores en cuanto a la forma de estructurar las simulaciones. «¿Escribes una regla de software basada en el conocimiento humano para restringir la IA o dejas que la IA aprenda por ensayo y error? Ese fue un gran debate interno. Cuando proporcionas reglas generales, limitas su rendimiento. Necesitan aprender por ensayo y error», dijo Ritholtz.
En última instancia, no se discute la rapidez con la que una IA puede aprender dentro de un área de esfuerzo definida, porque puede repetir la lección una y otra vez, en múltiples máquinas.
Lockheed, al igual que otros equipos, tenía como asesor a un piloto de caza. También fueron capaces de ejecutar conjuntos de entrenamiento en hasta 25 servidores DGx1 a la vez. Pero lo que finalmente produjeron se podía ejecutar un solo chip de GPU.
En comparación, después de la victoria, Ben Bell, el ingeniero senior de aprendizaje de máquinas de Heron Systems, dijo que su agente había pasado por al menos 4.000 millones de simulaciones y había adquirido al menos «12 años de experiencia».
No es la primera vez que la IA supera a un piloto de combate humano en un concurso. Una demostración en 2016 demostró que un agente llamado Alfa podía vencer a un experimentado instructor de vuelo de combate humano. Pero la simulación de DARPA del jueves fue posiblemente más significativa, ya que lanzó una variedad de agentes de IA entre sí y luego contra un humano en un marco altamente estructurado.
A los agentes IA no se les permitió aprender de sus experiencias durante las pruebas reales, lo que Bell dijo que era «un poco injusto». El concurso real lo confirmó. En la quinta y última ronda del combate, el piloto humano anónimo, Banger, pudo cambiar significativamente sus tácticas y durar mucho más tiempo. «Las cosas estándar que hacemos como pilotos de caza no están funcionando», dijo. Al final no importó. No había aprendido lo suficientemente rápido y fue derrotado.
Hay una gran elección a futuro que los militares tendrán que hacer. Permitir que la IA aprenda más en el combate real, en lugar de entre misiones y por lo tanto bajo supervisión humana directa, probablemente aceleraría el aprendizaje y ayudaría a los cazas no tripulados a competir aún mejor contra los pilotos humanos u otras IA. Pero eso implicaría una decisión humana, la cual saldría del proceso en un punto crítico. Ritholtz dijo que el enfoque que defendería, al menos en este momento, sería entrenar el algoritmo, desplegarlo, y luego «traer los datos de vuelta, aprender de ellos, entrenar de nuevo, volver a desplegar», en lugar de que el agente aprendiera en el aire.
Timothy Grayson, director de la Oficina de Tecnología Estratégica de DARPA, describió el ensayo como una victoria para una mejor combinación de humanos y máquinas en el combate, que era el verdadero punto. El concurso fue parte de un proyecto más amplio de DARPA llamado Air Combat Evolution, o ACE, que no necesariamente busca reemplazar a los pilotos con sistemas no tripulados, sino que busca automatizar muchas de sus tareas.
«Creo que lo que estamos viendo hoy es el comienzo de algo que voy a llamar la simbiosis hombre-máquina… Pensemos en el humano sentado en la cabina, volando por uno de estos algoritmos de IA como si fuera realmente un sistema de armas, donde el humano se centra en lo que el humano hace mejor [como el pensamiento estratégico de orden superior] y la IA hace lo que la IA hace mejor», dijo Grayson.
Sé el primero en comentar